网友您好, 请在下方输入框内输入要搜索的题目:
题目内容
(请给出正确答案)
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
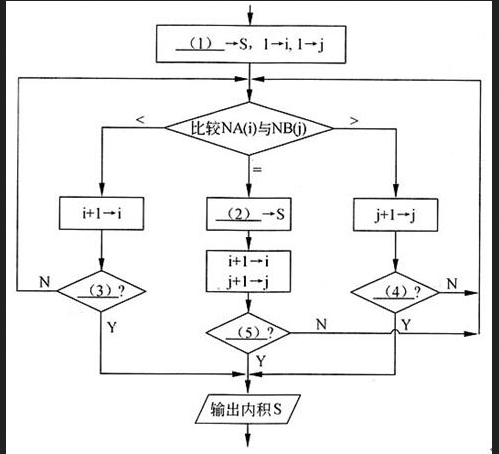
指定网页中,某个关键词出现的次数除以该网页长度称为该关键词在此网页中的词频。对新闻类网页,存在一组公共的关键词。因此,每个新闻网页都存在一组词频,称为该新闻网页的特征向量。
设两个新闻网页的特征向量分别为:甲(a1,a2,...,ak)、乙(b1,b2,...,bk),则计算这两个网页的相似度时需要先计算它们的内积S=a1b1+a2b2+...+akbk。一般情况下,新闻网页特征向量的维数是巨大的,但每个特征向量中非零元素却并不多。为了节省存储空间和计算时间,我们依次用特征向量中非零元素的序号及相应的词频值来简化特征向量。为此,我们用(NA(i),A(i)|i=1,2,...,m)和(NB(j),B(j)|j=1,2,...,n)来简化两个网页的特征向量。其中:NA(i)从前到后描述了特征向量甲中非零元素A(i)的序号(NA(1)<NA(2)<...),NB(j)从前到后描述了特征向量乙中非零元素B(j)的序号(NB(1)<NB(2)<...)。
下面的流程图描述了计算这两个特征向量内积S的过程。
[说明]
指定网页中,某个关键词出现的次数除以该网页长度称为该关键词在此网页中的词频。对新闻类网页,存在一组公共的关键词。因此,每个新闻网页都存在一组词频,称为该新闻网页的特征向量。
设两个新闻网页的特征向量分别为:甲(a1,a2,...,ak)、乙(b1,b2,...,bk),则计算这两个网页的相似度时需要先计算它们的内积S=a1b1+a2b2+...+akbk。一般情况下,新闻网页特征向量的维数是巨大的,但每个特征向量中非零元素却并不多。为了节省存储空间和计算时间,我们依次用特征向量中非零元素的序号及相应的词频值来简化特征向量。为此,我们用(NA(i),A(i)|i=1,2,...,m)和(NB(j),B(j)|j=1,2,...,n)来简化两个网页的特征向量。其中:NA(i)从前到后描述了特征向量甲中非零元素A(i)的序号(NA(1)<NA(2)<...),NB(j)从前到后描述了特征向量乙中非零元素B(j)的序号(NB(1)<NB(2)<...)。
下面的流程图描述了计算这两个特征向量内积S的过程。
参考答案
参考解析
解析:0
S+A(i)B(j) 或 等价表示
i>m或i=m+1或 等价表示
j>n或i=n+1 或 等价表示
i>m or j>n或i=m+1 or i=n+1 或等价表示
【解析】
本题是简化了的一个大数据算法应用之例。世界上每天都有大量的新闻网页,门户网站需要将其自动进行分类,并传送给搜索的用户。为了分类,需要建立网页相似度的衡量方法。流行的算法是,先按统一的关键词组计算各个关键词的词频,形成网页的特征向量,这样,两个网页特征向量的夹角余弦(内积/两个向量模的乘积),就可以衡量两个网页的相似度。因此,计算两个网页特征向量的内积就是分类计算中的关键。
对于存在大量零元素的稀疏向量来说,用题中所说的简化表示方法是很有效的。这样,求两个向量的内积只需要在分别从左到右扫描两个简化向量时,计算对应序号相同(NA(i)=NB(j))时的A(i)*B(j)之和(其他情况两个向量对应元素之乘积都是0)。因此,流程图中(2)处应填S+A(i)*B(j),而累计的初始值S应该为0,即(1)处应填0。
流程图中,NA(i)<NB(j)时,下一步应再比较NA(i+1)<NB(j),除非i+1已经越界。因此,应先执行i+1→i,再判断是否i>m或i=m+1(如果成立,则扫描结束)。因此(3)处应填i>m或i=m+1。
流程图中,NA(i)>NB(j)时,下一步应再比较NA(i)<NB(j+1),除非j+1已经越界。因此,应先执行j+1→j,再判断是否j>n或j=n+1(如果成立,则扫描结束)。因此(4)处应填j>n或j=n+1。
(5)处应填扫描结束的条件,i>m or j>13或i=m+1 or j=n+1,即两个简化向量之一扫描结束时,整个扫描就结束了。
S+A(i)B(j) 或 等价表示
i>m或i=m+1或 等价表示
j>n或i=n+1 或 等价表示
i>m or j>n或i=m+1 or i=n+1 或等价表示
【解析】
本题是简化了的一个大数据算法应用之例。世界上每天都有大量的新闻网页,门户网站需要将其自动进行分类,并传送给搜索的用户。为了分类,需要建立网页相似度的衡量方法。流行的算法是,先按统一的关键词组计算各个关键词的词频,形成网页的特征向量,这样,两个网页特征向量的夹角余弦(内积/两个向量模的乘积),就可以衡量两个网页的相似度。因此,计算两个网页特征向量的内积就是分类计算中的关键。
对于存在大量零元素的稀疏向量来说,用题中所说的简化表示方法是很有效的。这样,求两个向量的内积只需要在分别从左到右扫描两个简化向量时,计算对应序号相同(NA(i)=NB(j))时的A(i)*B(j)之和(其他情况两个向量对应元素之乘积都是0)。因此,流程图中(2)处应填S+A(i)*B(j),而累计的初始值S应该为0,即(1)处应填0。
流程图中,NA(i)<NB(j)时,下一步应再比较NA(i+1)<NB(j),除非i+1已经越界。因此,应先执行i+1→i,再判断是否i>m或i=m+1(如果成立,则扫描结束)。因此(3)处应填i>m或i=m+1。
流程图中,NA(i)>NB(j)时,下一步应再比较NA(i)<NB(j+1),除非j+1已经越界。因此,应先执行j+1→j,再判断是否j>n或j=n+1(如果成立,则扫描结束)。因此(4)处应填j>n或j=n+1。
(5)处应填扫描结束的条件,i>m or j>13或i=m+1 or j=n+1,即两个简化向量之一扫描结束时,整个扫描就结束了。
更多 “阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 [说明] 指定网页中,某个关键词出现的次数除以该网页长度称为该关键词在此网页中的词频。对新闻类网页,存在一组公共的关键词。因此,每个新闻网页都存在一组词频,称为该新闻网页的特征向量。 设两个新闻网页的特征向量分别为:甲(a1,a2,...,ak)、乙(b1,b2,...,bk),则计算这两个网页的相似度时需要先计算它们的内积S=a1b1+a2b2+...+akbk。一般情况下,新闻网页特征向量的维数是巨大的,但每个特征向量中非零元素却并不多。为了节省存储空间和计算时间,我们依次用特征向量中非零元素的序号及相应的词频值来简化特征向量。为此,我们用(NA(i),A(i)|i=1,2,...,m)和(NB(j),B(j)|j=1,2,...,n)来简化两个网页的特征向量。其中:NA(i)从前到后描述了特征向量甲中非零元素A(i)的序号(NA(1)<NA(2)<...),NB(j)从前到后描述了特征向量乙中非零元素B(j)的序号(NB(1)<NB(2)<...)。 下面的流程图描述了计算这两个特征向量内积S的过程。 ” 相关考题
考题
阅读以下说明和流程图,回答问题1~2,将解答填入对应的解答栏内。[说明]下面的流程图描述了计算自然数1到N(N≥1)之和的过程。[流程图][问题1] 将流程图中的(1)~(3)处补充完整。[问题2] 为使流程图能计算并输出1*3+2*4+…+N*(N+2)的值,A框内应填写(4);为使流程图能计算并输出不大于N的全体奇数之和,B框内应填写(5)。
考题
阅读以下说明和流程图,填补流程图中的空缺(1)一(5),将解答填入答题纸的对应栏内。【说明】下面的流程图采用公式ex=1+x+x2/2 1+x3/3 1+x4/4 1+…+xn/n!+???计算ex的近似值。设x位于区间(0,1),该流程图的算法要点是逐步累积计算每项xx/n!的值(作为T),再逐步累加T值得到所需的结果s。当T值小于10-5时,结束计算。【流程图】
考题
阅读下面的说明,回答问题1~问题4,将解答填入答题纸对应的解答栏内。[说明]阅读以下说明,回答问题1~问题4,将解答填入答题纸对应的解答栏内。windows Server 2003是一个多任务多用户的操作系统,能够以集中或分布的方式实现各种应用服务器角色,是目前应用比较广的操作系统之一。Windows内置许多应用服务功能,将下表中(1)~(5)处空缺的服务器名称填写在答题纸对应的解答栏内。(1)
考题
阅读以下说明和流程图,填补流程图中的空缺(1)~(9),将解答填入对应栏内。【说明】假设数组A中的各元素A(1),A(2),…,A(M)已经按从小到大排序(M≥1);数组B中的各元素B(1),B(2),…,B(N)也已经按从小到大排序(N≥1)。执行下面的流程图后,可以将数组A与数组B中所有的元素全都存入数组C中,且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序)。例如,设数组A中有元素:2,5, 6,7,9;数组B中有元素2,3,4,7:则数组C中将有元素:2,2,3,4,5,6,7, 7, 9。【流程图】
考题
阅读以下说明,回答问题1至问题3,将解答填入答题纸对应的解答栏内。[说明]某公司A楼高40层,每层高3.3米,同一楼层内任意两个房间最远传输距离不超过90米,A楼和B楼之间距离为500米,需在整个大楼进行综合布线,结构如下图所示。为满足公司业务发展的需要,要求为楼内客户机提供数据速率为100Mbit/s的数据、图像,及语音传输服务。综合布线系统由六个子系统组成,将图中(1)~(6)处空缺子系统的名称填写在答题纸对应的解答栏内。
考题
阅读以下说明和流程图,回答问题1-2,将解答填入对应的解答栏内。[说明]下面的流程图采用欧几里得算法,实现了计算两正整数最大公约数的功能。给定正整数m和 n,假定m大于等于n,算法的主要步骤为:(1)以n除m并令r为所得的余数;(2)若r等于0,算法结束;n即为所求;(3)将n和r分别赋给m和n,返回步骤(1)。[流程图][问题1] 将流程图中的(1)~(4)处补充完整。[问题2] 若输入的m和n分别为27和21,则A中循环体被执行的次数是(5)。
考题
阅读下列说明,回答问题1至问题2,将解答填入答题纸的对应栏内。[说明]小舟很喜欢网上购物,不但自己经常上网买东西,还自己经营了一家商业网站,大到卖电器,衣物,小到可以和注册用户交换东西等等。图2-15是网上小舟经营的网站的购物流程图,请把空缺的部分补充完整。
考题
阅读以下说明和流程图,回答问题,并将解答填入对应栏内。【说明】求解约瑟夫环问题。算法分析:n个士兵围成一圈,给他们依次编号,班长指定从第w个士兵开始报数,报到第s个士兵出列,依次重复下去,直至所有士兵都出列。【流程图】【问题】将流程图中的(1)~(5)处补充完整。
考题
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 下面流程图的功能是:在给定的一个整数序列中查找最长的连续递增子序列。设序列存放在数组 A[1:n](n2)中,要求寻找最长递增子序列 A[K: K+L-1] (即A[K]A[K+1]A[K+L-1])。流程图中,用 Kj 和Lj 分别表示动态子序列的起始下标和长度,最后输出最长递增子序列的起始下标 K 和长度 L。 例如,对于序列 A={1 ,2,4,4 ,5,6,8,9,4,5,8},将输出K=4, L=5。【流程图】注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为: 循环控制变量=初值,终值
考题
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。 【说明】 设有整数数组A[1:N](N1),其元素有正有负。下面的流程图在该数组中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标K、元素个数L以及最大的和值M。 例如,若数组元素依次为3,-6,2,4,-2,3,-1,则输出K=3,L=4,M=7。该流程图中考察了A[1:N]中所有从下标i到下标j(ji)的各元素之和S,并动态地记录其最大值M。【流程图】注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1,格式为:循环控制变量=初值,终值
考题
试题一(共15分)阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的对应栏内。【说明】两个包含有限个元素的非空集合A、B的相似度定义为IAUBI/IA U Bl,即它们的交集大小(元素个数)与并集大小之比。以下的流程图计算两个非空整数集合(以数组表示)的交集和并集,并计算其相似度。己知整数组A[1:m】和B【1:n】分别存储了集合A和B的元素(每个集合中包含的元素各不相同),其交集存放于数组C[1:s】,并集存放于数组D【1:t】,集合A和B的相似度存放于SIM。例如,假设A={1,2,3,4},B={1,4,5,6},则C={1,4},D={1,2,3,4,5,6},A与B的相似度SIM=1/3。
考题
?????? 阅读以下说明和流程图,填补流程图中的空缺(1)~(5),将解答填入答题纸的对应栏内。【说明】本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾依次分离出各个关键词{A(i)li=l,…,n}(n>1)}.其中包含了很多重复项,经下面的流程处理后,从中挑选出所有不同的关键词共m个{K(j)[j=l,…,m},而每个关键词K(j)出现的次数为NK(j).j=l,…,m。??????
考题
阅读以下说明和Java程序,填补代码中的空缺(1)~(6),将解答填入答题纸的对应栏内。【说明】很多依托扑克牌进行的游戏都要先洗牌。下面的Java代码运行时先生成一副扑克牌,洗牌后再按顺序打印每张牌的点数和花色。【Java代码】
考题
试题一(共 15 分)阅读以下说明和流程图,填补流程图中的空缺(1)~(9) ,将解答填入答题纸的对应栏内。[说明]假设数组 A 中的各元素 A(1),A(2) ,…,A(M)已经按从小到大排序(M≥1) ;数组 B 中的各元素 B(1),B(2),…,B(N)也已经按从小到大排序(N≥1) 。执行下面的流程图后, 可以将数组 A 与数组 B 中所有的元素全都存入数组 C 中, 且按从小到大排序 (注意:序列中相同的数全部保留并不计排列顺序) 。例如,设数组 A 中有元素:2,5,6,7,9;数组B 中有元素:2,3,4,7;则数组 C 中将有元素:2,2,3,4,5,6,7,7,9。[流程图]
考题
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
两个包含有限个元素的非空集合A、B的相似度定义为|A∩B|/|A∪B|,即它们的交集大小(元素个数)与并集大小之比。
以下的流程图计算两个非空整数集合(以数组表示)的交集和并集,并计算其相似度。已知整数组A[1:m]和B[1:n]分别存储了集合A和B的元素(每个集合中包含的元素各不相同),其交集存放于数组C[1:s],并集存放于数组D[1:t],集合A和B的相似度存放于SIM。
例如,假设A={1,2,3,4},B={1,4,5,6},则C={1,4),D={1,2,3,4,5,6},A与B的相似度SIM=1/3。
[流程图]
考题
阅读下列说明和流程图,填补流程图中的空缺(1)~(9),将解答填入答题纸的对应栏内。【说明】假设数组A中的各元素A⑴,A (2),…,A (M)已经按从小到大排序(M>1):数组B中的各元素B(1) , B (2) . B (N)也已经按从小到大排序(N≥1)。执行下面的流程图后,可以将数组A与数组B中所有的元素全都存入数组C中,且按从小到大排序(注意:序列中相同的数全部保留并不计排列顺序)。例如,设数组A中有元素: 2,5,6,7,9;数组B中有元素: 2,3,4,7;则数组C中将有元素: 2,2,3,4,5,6,7,7,9.
考题
阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
[说明]
本流程图旨在统计一本电子书中各个关键词出现的次数。假设已经对该书从头到尾依次分离出各个关键词{A(i)|i=1,…,n}(n>1)},其中包含了很多重复项,经下面的流程处理后,从中挑选出所有不同的关键词共m个{K(j)|j=1,…,m},而每个关键词K(j)出现的次数为NK(j),j=1,…,m。
[流程图]
考题
阅读说明和流程图,填补流程图中的空缺(1)?(5),将答案填入答题纸对应栏内。【说明】本流程图用于计算菲波那契数列{a1=1,a2=1,…,an=an-1+an-2!n=3,4,…}的前n项(n>=2) 之和S。例如,菲波那契数列前6项之和为20。计算过程中,当前项之前的两项分别动态地保存在变量A和B中。【流程图】
考题
试题(15 分)阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏 内。【说明】设有整数数组 A[1:N](N>1),其元素有正有负。下面的流程图在该数组 中寻找连续排列的若干个元素,使其和达到最大值,并输出其起始下标 K、元素 个数 L 以及最大的和值 M。例如,若数组元素依次为 3,-6,2,4,-2,3,-1,则输出 K=3,L=4,M=7。 该流程图中考察了 A[1:N]中所有从下标 i 到下标 j(j≥i)的各元素之和 S,并动态地记录其最大值 M。【流程图】
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为 1,格式为:循环控制变量=初值,终值
考题
第一题 阅读以下说明和流程图,填补流程图中的空缺,将解答填入答题纸的对应栏内。
【说明】
对于大于1的正整数n,(x+1)n可展开为
问题:1.1 【流程图】
注:循环开始框内应给出循环控制变量的初值和终值,默认递增值为1。
格式为:循环控制变量=初值,终值,递增值。
考题
阅读以下说明,回答问题1至问题4,将解答填入答题纸对应的解答栏内。
【说明】
某企业网络拓扑如图1-1所示,A~E是网络设备的编号。
热门标签
最新试卷